
之前介紹過中文歌聲生成AI「雅婷」還沒看過的傳送門在此。今天要介紹的是日文版的雅婷「NEUTRINO」。他的功能基本上就跟雅婷一樣,也完全免費,還有免費的多組聲音model可選,實在是非常佛心來的。但也有個小缺點,就是必須下載,且沒有圖形介面,只能透過終端機 command line 來下指令。
安裝
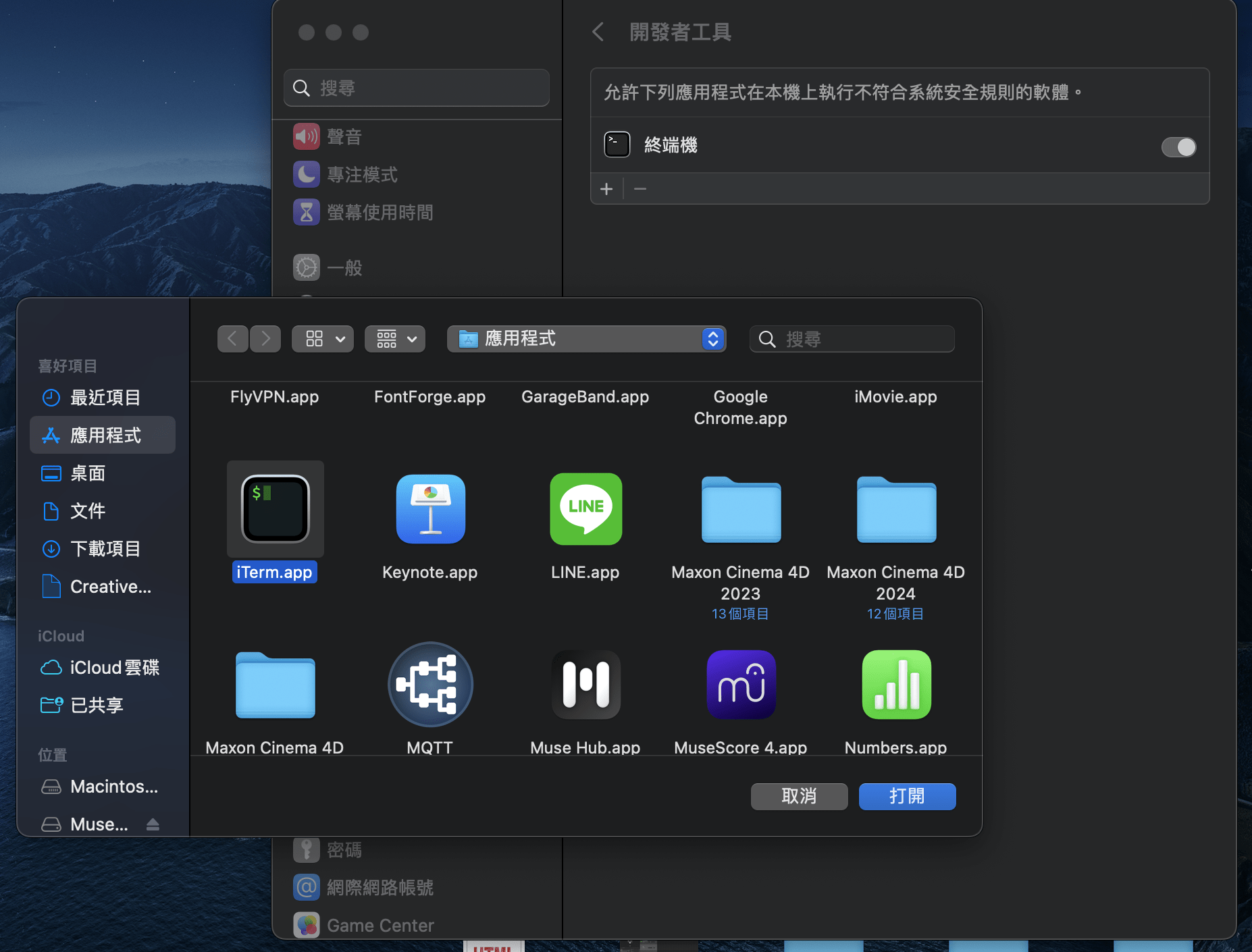
先到官網下載符合你作業系統的版本。接下來,我們要做的是只需要解壓縮,不需要執行任何安裝作業。我們等一下生成時要用到終端機,Mac的使用者(Windows的使用者可以略過這段)必須先到系統設定 -> 隱私權與安全性 -> 開發者工具,打開終端機的 switch button,如果是用 iTerm 的使用者,需要按一下終端機下面的加號,新增 iTerm 後打開 switch button 即可開始使用,不然會有安全性報錯。
使用
首先,我們先來完整進行一次從準備素材到輸出生成的流程,後面的章節再來仔細介紹各個可微調的細節。
與雅婷不同的地方還有一個,NEUTRINO 不吃 midi 檔,只吃 musicxml 檔。因此上次介紹的網頁版 midi 編輯器這次派不上用場。我們可以安裝另一個免費且大家都愛用的軟體「MuseScore」。MuseScore 跟上次介紹的Midi編輯器不同的是,上次的編輯器像 GarageBand一樣,用格子來拖拉音階,MuseScore 則是直接在五線譜上編輯。但在此就不多介紹 MuseScore 的基本操作方式了,不然可能要寫個兩萬字。以下只會列出關於 NEUTRINO 所要的格式的相關資訊。
我們最好在頭跟尾各留一個小節的空拍,不然輸出時會報個警告,然後他會跟你說他幫你補上了。不過似乎也是不影響結果拉,至少目前沒有遇到什麼問題。
當我們都輸入完音符後,就對每個音,分別加上要唱的假名。點選一個音符,按下 ctrl+l (mac command+l) 輸入假名。要每個音分開做,這樣才會知道哪個音要唱哪個假名。這邊要注意的是:當「は」唸成「ワ」的時候一定要打成「わ」不然會唱成「ha」。其他例如「へ」唸成「エ」時也要打成「え」不然會唱成「he」。更多輸入假名的規則後面的章節會更詳細介紹。
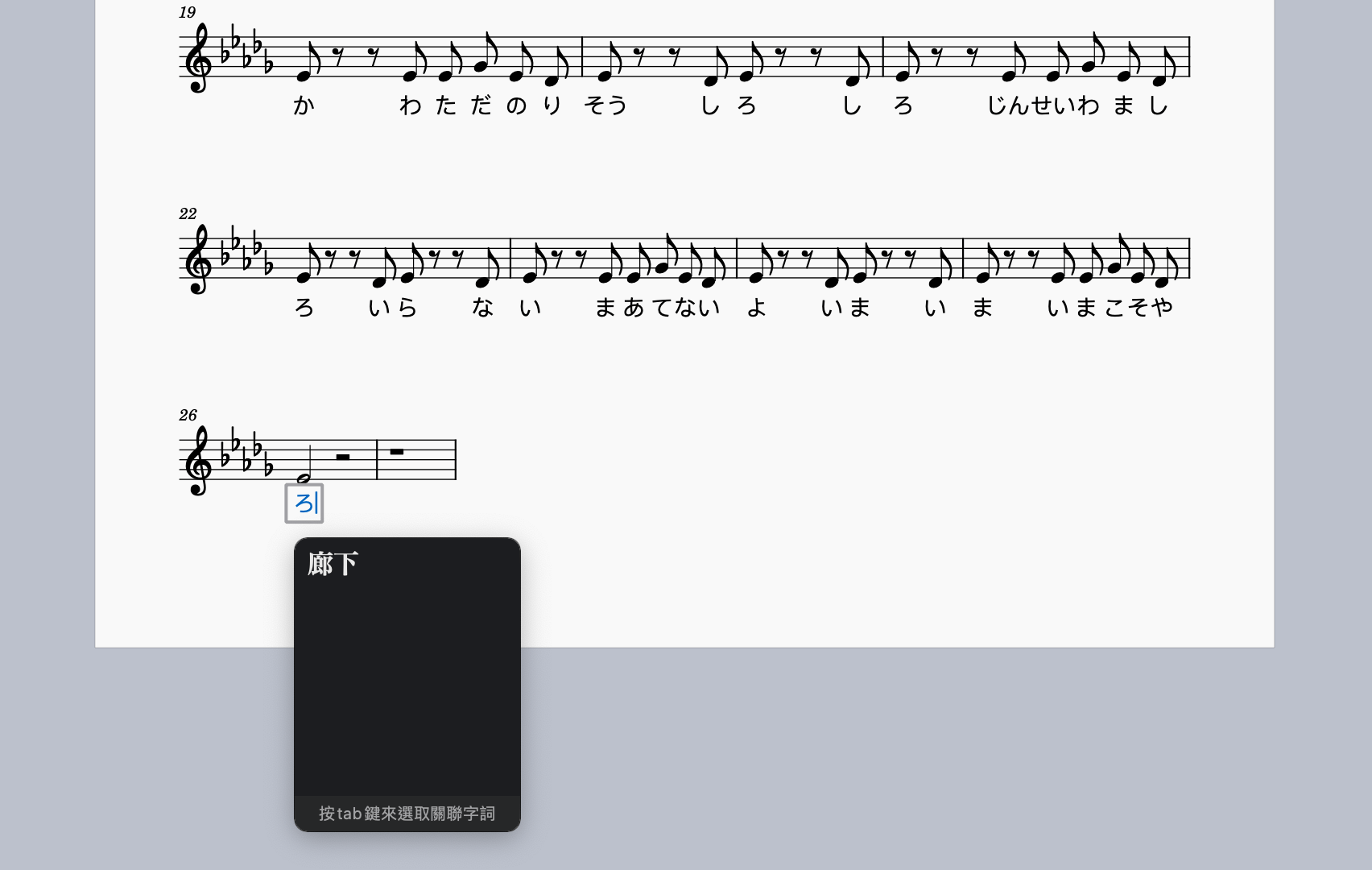
另外,我目前測試過裝飾音(又稱倚音,如下面紅色處)、滑音、顫音等等,目前似乎都是起不了任何作用的。

關於呼吸聲
NEUTRINO不像雅婷一樣,自動會在適合的地方加上呼吸聲,我們必須要用呼吸聲符號,來告訴NEUTRINO哪個地方要換氣。如下圖,先在左邊記號面板新增「呼吸與停頓」面板,選取要換氣的音符或休止符,再按一下左邊面板上的逗點換氣符號即可。

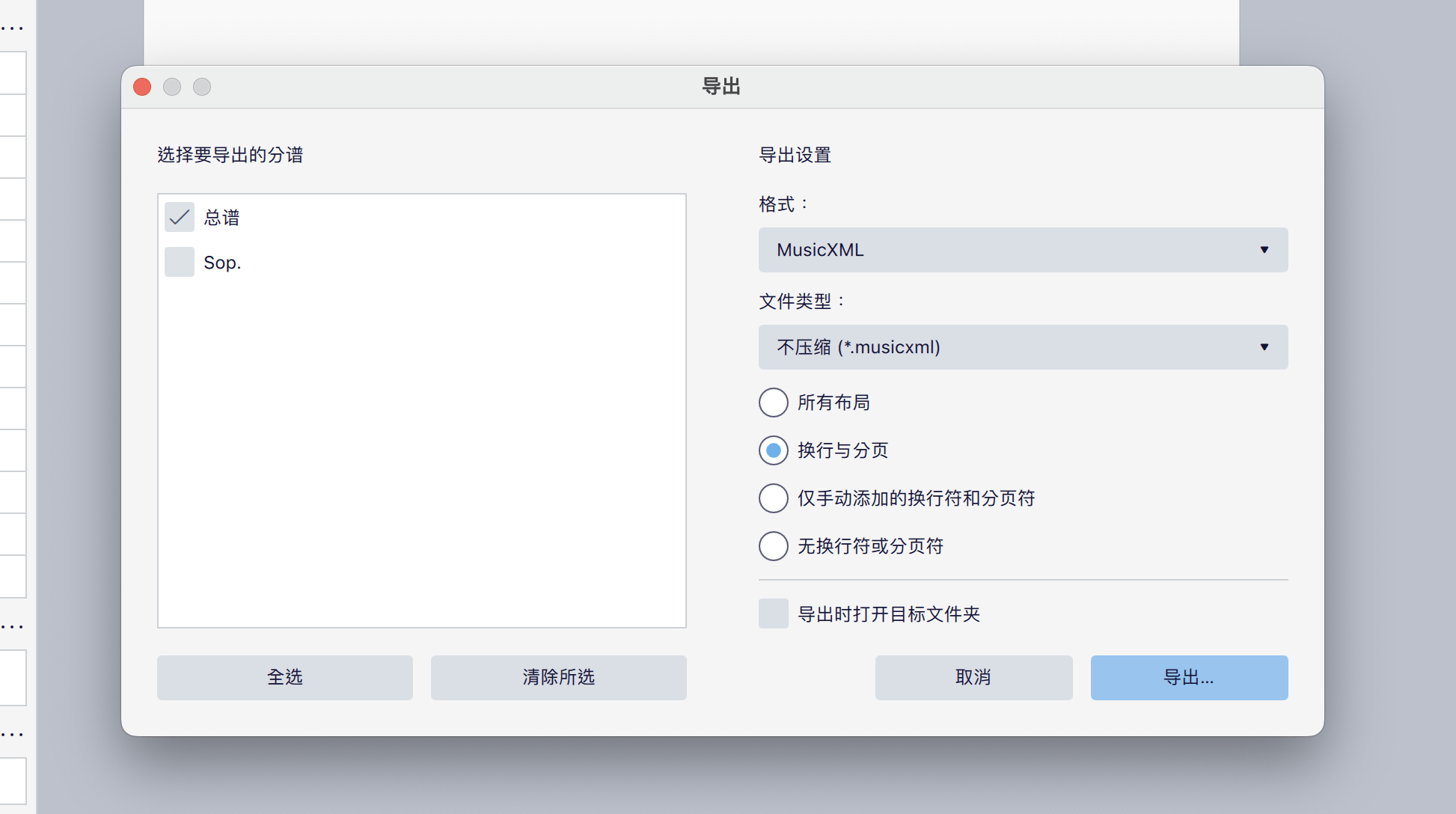
拍速、音符、歌詞全都搞定後,我們就要來輸出成 musicxml 檔拉。點選 文件 -> 導出,格式選擇 MusicXML,文件類型選擇「不壓縮 (*.musicxml)」按下導出即可。
接著我們把導出的檔案放到 NEUTRINO 的 score/musicxml 資料夾中。用純文字工具打開 NEUTRINO 根目錄的 Run.sh(windows 是Run.bat) 檔案。將 BASENAME=sample1 的 sample1 換成剛剛放進去的 musicxml 檔案的檔名(不需副檔名)如下:
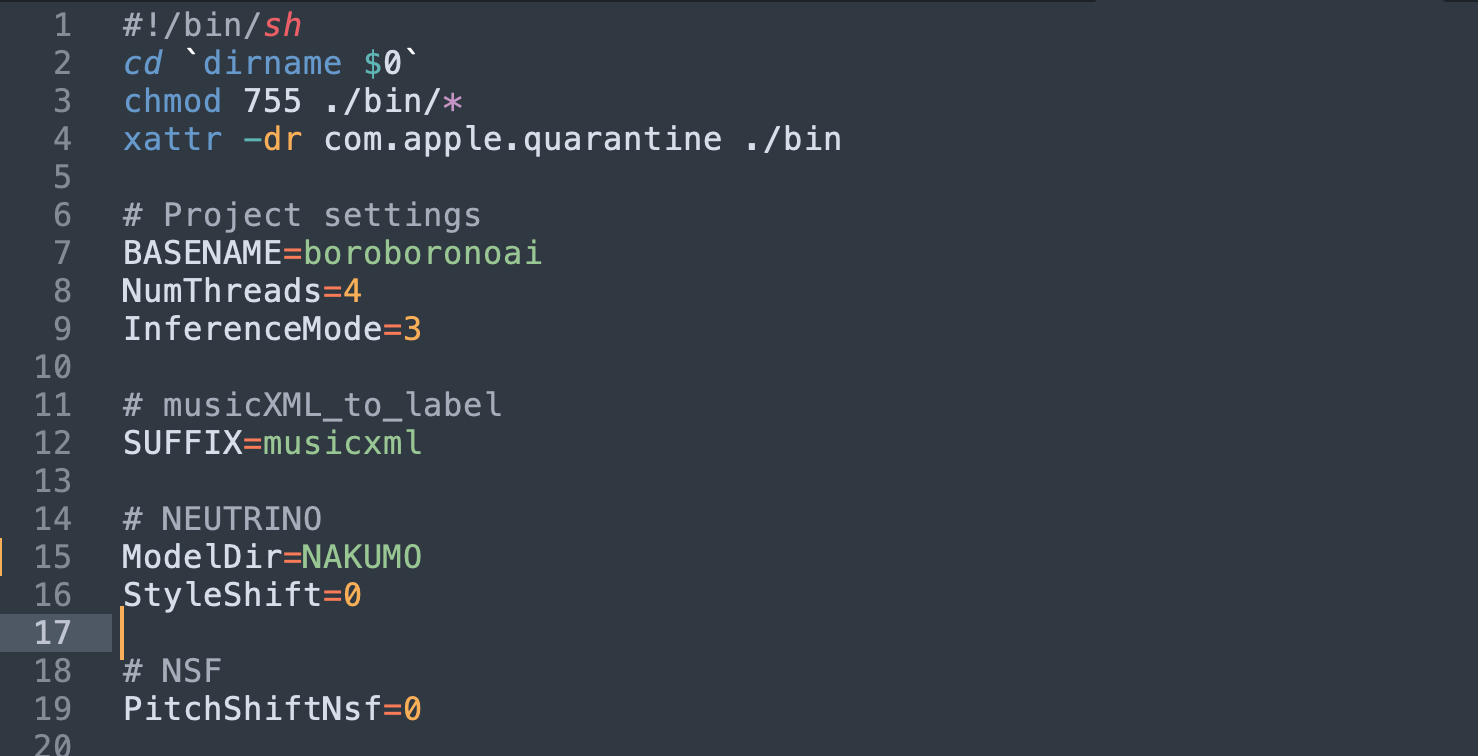
接著打開終端機(Windows 使用者在執行打cmd就可以打開終端機視窗)輸入 cd 你的 NEUTRINO 資料夾位置, 執行 sh Run.sh (windows 輸入 Run.bat)就會開始跑了。運算的時間視你的歌曲長度而定。跑完之後我們打開 NEUTRINO 資料夾中的 output 資料夾,就可以看到輸出成果的wav檔了。輸出後會得到兩個 .wav 檔,一個是 xxx.wav(NSF模式)另一個是 xxx_world.wav(world模式),是由兩種不同的運算方式產出的結果。world模式據說可以修正一些嘶啞或超過能力範圍的聲音缺陷,但我覺得NSF模式產出的品質通常比較好。
一樣附上我測試的歌曲,這是我用我極少的日文單字量來改寫眉飛色舞的歌詞,編曲是用 GarageBand 做的。連結:https://www.facebook.com/boggyjan/videos/358709993511097/
與雅婷比較
日文版(model: 歌声ライブラリ – No.7)
雅婷男版model,高音會走音
雅婷女版model,整體不錯但結尾有奇怪的pitch偏移
日版在呼吸聲的部分很明顯沒有聽到,可能旋律太過緊湊而被判斷成會不自然。不過我改用生物股長的ありがとう這首歌來測試,又很明顯可以聽到呼吸聲。
安裝更多聲音model
剛剛前面有提到,還有非常多免費的聲音 model 可以下載,目前總共有13種可以下載。官網上點選圖片可以試聽。我目前試過了預設的「めろう」還有「ナクモ」「No.7」每一個產出的結果,差異都非常大很有特色。對於簡單地做 demo 來說,應該算是很夠用了。接下來介紹 model 的安裝。
在官網下載完後,將檔案解壓縮,把解壓縮完的目錄中的目錄(例如 No.7這個model 裡面的目錄叫做SEVEN)放到 NEUTRINO 的model目錄中。我們再用文字編輯器打開 Run.sh 修改 ModelDir=MERROW 的 MERROW 改成你剛剛丟進去的目錄名稱,例如 SEVEN。然後再到終端機執行一次 sh Run.sh 就可以了。
詳細變數設定說明
| 類型 | 變數 | 預設值 | 允許值 | 說明與備註 |
| 專案設定 | BASENAME | sample1 | 任意字串 | 不包含副檔名的檔名 |
| NumThreads | 4 | 任意正整數 | 使用幾個執行緒 | |
| InferenceMode | 3 | 4.高品質 48kHz 用GPU 3.一般版 48kHz 用CPU 2.高速 24kHz 適合低階CPU | 設定處理速度、品質 | |
| SUFFIX | musicxml | musicxml or xml | 副檔名 | |
| Model | ModelDir | MERROW | 任意字串 | 使用哪個資料夾名稱的model |
| StyleShift | 0 | -5 ~ 5 | 指的是用移調後的演唱風格來唱(但不會真的移調)但我聽不出來 | |
| NSF | PitchShiftNsf | 0 | 任意正負數字 | 移調 例:1.0 or -1.0 |
| WORLD | PitchShiftWorld | 0 | 任意正負數字 | 從這行以下的變數都只會反映在產出的 xxx_world.wav 檔中,對 xxx.wav 不會有影響 可以將PitchShiftNsf與PitchShiftWorld設成相同的值,比較產出的xxx.wav與xxx_world.wav,測試後WORLD跟NSF不同的地方是,WORLD在超過能力範圍的高音比較不會出現沙啞的聲音,但偶爾也會有不自然的現象。 |
| FormantShift | 1.0 | 任意正負數字 | 改變聲調寬扁度。數值越大會越像小孩,越小會越像大人(因為正負0.2就已經會差很多了,建議從小幅度的調整開始試) | |
| SmoothPitch | 0.0 | 0~100 | 改變音與音之間的平滑度,開太大唱起來會偏油 | |
| SmoothFormant | 0.0 | 0~100 | 平滑聲音的寬扁度,我目前測起來聽不出差別 | |
| EnhanceBreathiness | 0.0 | 0~100 | 呼吸強弱,官方twitter上表示「特別是在東北ずん子與めろう這兩個model上,唱慢歌時能有效的呈現呼吸聲的差異」 |
假名的詳細規則
- 歌詞請使用發音方式的全形假名,例如:「♪わ ♪た ♪し ♪は」要改成「♪わ ♪た ♪し ♪わ」,「♪き ♪ょ ♪う ♪も」要改成「♪き ♪ょ ♪お ♪も」
- 使用長音符號「ー」時,會延續前一個字的母音繼續唱下去。例如:「♪ス ♪タ ♪ー ♪ト」會變成「♪ス ♪タ ♪ア ♪ト」
- 使用促音符號「っ」時,會延續前一個字的母音加上促音來唱。例如:「♪き ♪っ ♪と」會變成「♪き ♪いっ ♪と」
- 使用去母音記號「’」可以只唱出子音。例如:「♪いつ’(注意要在同一個音) ♪か」會變成「♪いts ♪か」